|
|
||
|---|---|---|
| .github/workflows | ||
| .vscode | ||
| ci | ||
| doc | ||
| exampledir | ||
| src | ||
| .gitignore | ||
| Cargo.lock | ||
| Cargo.toml | ||
| CHANGELOG.md | ||
| LICENSE.md | ||
| README.md | ||
| rust-toolchain | ||
| rustfmt.toml | ||
rga: ripgrep, but also search in PDFs, E-Books, Office documents, zip, tar.gz, etc.
rga is a line-oriented search tool that allows you to look for a regex in a multitude of file types. rga wraps the awesome ripgrep and enables it to search in pdf, docx, sqlite, jpg, movie subtitles (mkv, mp4), etc.
![]()

![]()
For more detail, see this introductory blogpost: https://phiresky.github.io/blog/2019/rga--ripgrep-for-zip-targz-docx-odt-epub-jpg/
rga will recursively descend into archives and match text in every file type it knows.
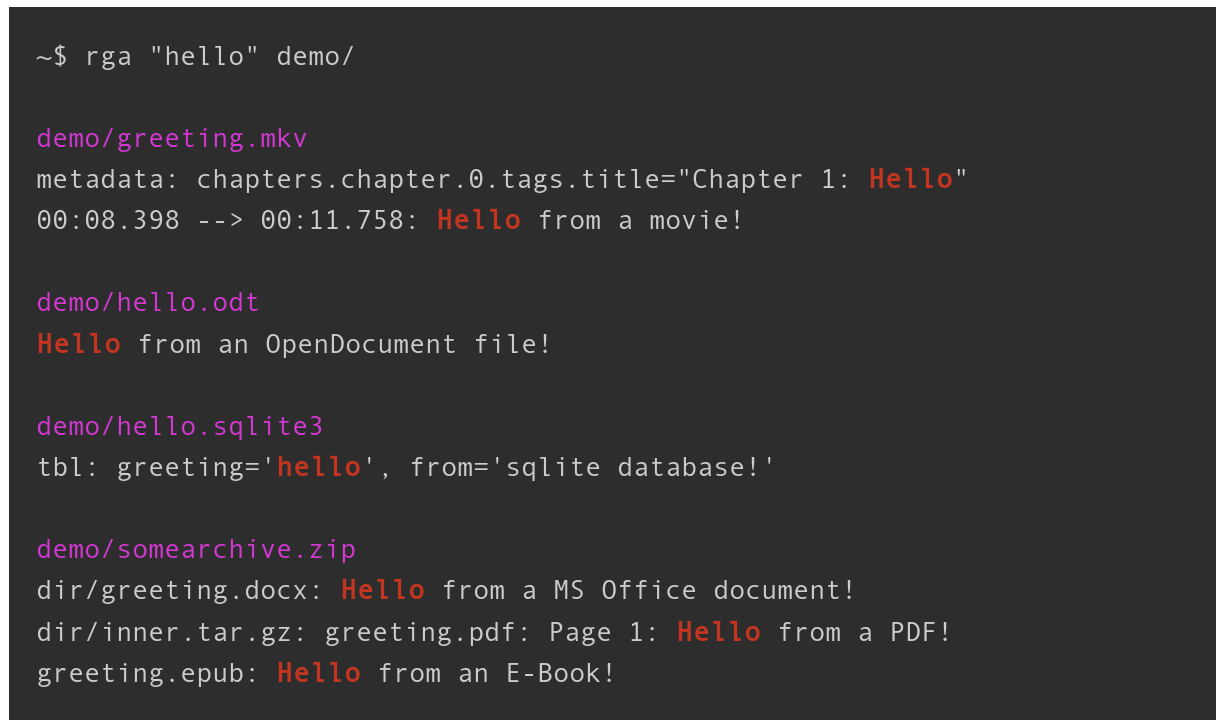
Here is an example directory with different file types:
demo/
├── greeting.mkv
├── hello.odt
├── hello.sqlite3
└── somearchive.zip
├── dir
│ ├── greeting.docx
│ └── inner.tar.gz
│ └── greeting.pdf
└── greeting.epub
Integration with fzf

You can use rga interactively via fzf. Add the following to your ~/.{bash,zsh}rc:
rga-fzf() {
RG_PREFIX="rga --files-with-matches"
local file
file="$(
FZF_DEFAULT_COMMAND="$RG_PREFIX '$1'" \
fzf --sort --preview="[[ ! -z {} ]] && rga --pretty --context 5 {q} {}" \
--phony -q "$1" \
--bind "change:reload:$RG_PREFIX {q}" \
--preview-window="70%:wrap"
)" &&
echo "opening $file" &&
xdg-open "$file"
}
INSTALLATION
Linux x64, macOS and Windows binaries are available in GitHub Releases.
Linux
Arch Linux
simply install from AUR: yay -S ripgrep-all.
Nix
nix-env -iA nixpkgs.ripgrep-all
Debian-based
download the rga binary and get the dependencies like this:
apt install ripgrep pandoc poppler-utils ffmpeg
If ripgrep is not included in your package sources, get it from here.
rga will search for all binaries it calls in $PATH and the directory itself is in.
Windows
Install ripgrep-all via Chocolatey:
choco install ripgrep-all
Note that installing via chocolatey or scoop is the only supported download method. If you download the binary from releases manually, you will not get the dependencies (for example pdftotext from poppler).
If you get an error like VCRUNTIME140.DLL could not be found, you need to install vc_redist.x64.exe.
Homebrew/Linuxbrew
rga can be installed with Homebrew:
brew install rga
To install the dependencies that are each not strictly necessary but very useful:
brew install pandoc poppler tesseract ffmpeg
Compile from source
rga should compile with stable Rust (v1.36.0+, check with rustc --version). To build it, run the following (or the equivalent in your OS):
~$ apt install build-essential pandoc poppler-utils ffmpeg ripgrep cargo
~$ cargo install ripgrep_all
~$ rga --version # this should work now
Available Adapters
rga --rga-list-adapters
Adapters:
- ffmpeg
Uses ffmpeg to extract video metadata/chapters and subtitles
Extensions: .mkv, .mp4, .avi
- pandoc
Uses pandoc to convert binary/unreadable text documents to plain markdown-like text
Extensions: .epub, .odt, .docx, .fb2, .ipynb
-
poppler Uses pdftotext (from poppler-utils) to extract plain text from PDF files
Extensions: .pdf
Mime Types: application/pdf -
zip Reads a zip file as a stream and recurses down into its contents
Extensions: .zip
Mime Types: application/zip -
decompress Reads compressed file as a stream and runs a different extractor on the contents.
Extensions: .tgz, .tbz, .tbz2, .gz, .bz2, .xz, .zst
Mime Types: application/gzip, application/x-bzip, application/x-xz, application/zstd -
tar Reads a tar file as a stream and recurses down into its contents
Extensions: .tar
- sqlite
Uses sqlite bindings to convert sqlite databases into a simple plain text format
Extensions: .db, .db3, .sqlite, .sqlite3
Mime Types: application/x-sqlite3
The following adapters are disabled by default, and can be enabled using '--rga-adapters=+pdfpages,tesseract':
-
pdfpages Converts a pdf to its individual pages as png files. Only useful in combination with tesseract
Extensions: .pdf
Mime Types: application/pdf -
tesseract Uses tesseract to run OCR on images to make them searchable. May need -j1 to prevent overloading the system. Make sure you have tesseract installed.
Extensions: .jpg, .png
USAGE:
rga [RGA OPTIONS] [RG OPTIONS] PATTERN [PATH ...]
FLAGS:
--rga-accurate
Use more accurate but slower matching by mime type
By default, rga will match files using file extensions. Some programs, such as sqlite3, don't care about the file extension at all, so users sometimes use any or no extension at all. With this flag, rga will try to detect the mime type of input files using the magic bytes (similar to the `file` utility), and use that to choose the adapter. Detection is only done on the first 8KiB of the file, since we can't always seek on the input (in archives).
-h, --help
Prints help information
--rga-list-adapters
List all known adapters
--rga-no-cache
Disable caching of results
By default, rga caches the extracted text, if it is small enough, to a database in ~/.cache/rga on Linux, ~/Library/Caches/rga on macOS, or C:\Users\username\AppData\Local\rga on Windows. This way, repeated searches on the same set of files will be much faster. If you pass this flag, all caching will be disabled.
--rg-help
Show help for ripgrep itself
--rg-version
Show version of ripgrep itself
-V, --version
Prints version information
OPTIONS:
--rga-adapters=<adapters>...
Change which adapters to use and in which priority order (descending)
"foo,bar" means use only adapters foo and bar. "-bar,baz" means use all default adapters except for bar and baz. "+bar,baz" means use all default adapters and also bar and baz.
--rga-cache-compression-level=<cache-compression-level>
ZSTD compression level to apply to adapter outputs before storing in cache db
Ranges from 1 - 22 [default: 12]
--rga-cache-max-blob-len=<cache-max-blob-len>
Max compressed size to cache
Longest byte length (after compression) to store in cache. Longer adapter outputs will not be cached and recomputed every time. Allowed suffixes: k M G [default: 2000000]
--rga-max-archive-recursion=<max-archive-recursion>
Maximum nestedness of archives to recurse into [default: 4]
-h shows a concise overview, --help shows more detail and advanced options.
All other options not shown here are passed directly to rg, especially
PATTERNDevelopment
To enable debug logging:
export RUST_LOG=debug
export RUST_BACKTRACE=1
Also remember to disable caching with --rga-no-cache or clear the cache
(~/Library/Caches/rga on macOS, ~/.cache/rga on other Unixes,
or C:\Users\username\AppData\Local\rga on Windows)
to debug the adapters.